Развитие идей ООП с попутным отбрасыванием лишнего
Может ли быть технология программирования лучше чем объектно-ориентированная,
и если может, то какая.
Статья опубликована в журнале «Технология клиент/сервер» за 1кв. 2004г.
| Клянусь, что замышляю шалость и только шалость. (заклинание карты мародёров) |
Содержание
Вступление
Основные понятия
Классификация объектов
Наследование
Агрегация
Mixin-технология
Что же предлагается?
Синергизм классов
Абстрактные классы
Шаблоны (templates)
Реализации интерфейсов при множественной классификации
Статические и динамические методы
Мутация объектов
Строгая типизация
Реляционные БД и множественная классификация
Изменения в технологии проектирования
Что дальше?
Заключение
Объектно-ориентированная технология разработки программ стала стандартом де-факто, используемым подавляющим большинством разработчиков. За время своего существования она получила мощную методологическую поддержку и поддержку со стороны разработчиков инструментальных средств. По сути, про ООП сейчас можно говорить не только как о концепции и методологии, но и как о своего рода религии, имеющей, как это и положено, своих пророков, миссионеров, адептов и еретиков.
Тем не менее, стоит сказать, что всякая технология имеет границы своей применимости. Об этом необходимо помнить и специалистам по металлообработке, и медикам, и программистам.
Обычно декларируются следующие преимущества использования технологии объектно-ориентированного программирования:
- Возможность программирования в понятиях, максимально приближенных к предметной области.
- Многократное использование единожды написанного кода.
- Модульность программ.
По всем трём пунктам ООП явилось огромным шагом вперёд по сравнению с применявшимся ранее процедурным подходом. ООП нашло широкое и весьма эффективное применение в системном программировании, программировании пользовательских интерфейсов прикладных программ. Но интересно не это, а то, что ООП не нашло достойного применения в некоторых прикладных областях. Например, несмотря на все усилия (в том числе и маркетинговые), ООП полноценно не применяется при проектировании бизнес-логики автоматизированных систем управления предприятиями. И это при том, что на недостаток квалификации проектировщиков и программистов это положение дел вряд ли удастся списать, так как рынок систем автоматизации является высококонкурентным, туда привлечены весьма серьёзные материальные и интеллектуальные ресурсы.
Несмотря на всё богатство методологии, многие задачи просто не могут быть адекватно и удобно описаны в рамках объектно-ориентированного подхода. Может быть, многие проблемы современной индустрии софтостроения кроются в теоретических просчётах, спрятанных глубоко в фундаменте объектно-ориентированной технологии?
Начнём, как водится, с определений (путаться в понятиях – последнее дело), потом разложим по косточкам очень скользкое и неоднозначное понятие класса. Кстати, именно в понятии класса я и нашёл очень неприятную идеологическую недоработку ООП. Дальнейшее повествование сводится к латанию этой дыры и вольным фантазиям на тему того, как хотелось бы жить дальше.
Основные понятия
В этом разделе я ничего нового не скажу. Просто приведу список понятий, которыми буду в дальнейшем оперировать.
Объект, экземпляр – информационная сущность, которой можно оперировать как единым целым.
Заметьте, что под понятием «Объект» здесь подразумевается не тип данных, а именно экземпляр (instance). Например, дата – это не объект (а класс, но понятием класса сейчас голову не забиваем, а подойдём к нему позже), а переменная, содержащая значение 01.04.2003 – это объект; целое число – не объект, а переменная, содержащая целое число 8934 – объект.
Интерфейс объекта – способ информационного воздействия на него. Например, «Установить реквизит», «Получить реквизит», «Инициализировать», «Распечатать», «Отформатировать», «Обработать текстовый запрос».
Если что-то хочется сделать с объектом, нужно обращаться к его интерфейсу (вот она, инкапсуляция). Иного способа взаимодействия кроме как через интерфейс, нет. Интерфейсом, например, может быть процедура, функция, свойство, public переменная.
В интерфейсном программировании под понятием «интерфейс» подразумевается нечто другое, по своей семантике больше похожее на класс. В этом тексте интерфейс – это именно процедура, функция, свойство и т.д.
Реализация интерфейса – алгоритм, который будут выполнен при вызове интерфейса.
Классификация объектов
Работа программы – это выполнение кода, инкапсулированного в объекты и взаимодействие объектов между собой. Взаимодействие объектов – это вызов интерфейсов.
Для того, чтобы вызывающий объект мог взаимодействовать с вызываемым, вызывающий должен обладать некоторым набором сведений о вызываемом. Это может быть изначальное знание перечня необходимых интерфейсов либо некий протокол запроса сведений.
Изначальное знание всех необходимых интерфейсов – это знание типа объекта или, как принято выражаться, класса. Например, объект А знает, что объект Б имеет тип Поставщик и, соответственно, весь тот набор интерфейсов, которые обычно присущи поставщикам. Даже если в системе программирования вовсе нет механизма типизации (скажу честно, таких прецедентов я не знаю), типизация всё равно неявно присутствует. В принципе, конечно, каждый объект может иметь собственный, свойственный только ему набор интерфейсов и/или их реализаций (т.е. классов в программе столько же, сколько и объектов), но это экзотика.
Итак, принадлежность объекта к классу означает, что объект имеет набор интерфейсов, специфичных для данного класса и выполняющих именно те функции, которые для него подразумеваются.
Может ли объект принадлежать одновременно к нескольким классам? Однозначный ответ – да. Более того, подавляющее большинство объектов принадлежат нескольким классам. В классическом ООП вопрос множественной классификации решается на уровне описаний классов (наследование либо агрегация).
 Наследование – это заложенный в методологию ООП способ объявить тот факт,
что всякий объект класса X также является и объектом класса Y. То есть если у нас есть класс
"собака", то в описании классов записано, что каждый объект этого класса также принадлежит классу
"млекопитающее", каждое млекопитающее также принадлежит классу "животное", каждое животное также принадлежит
некоему базовому классу "объект". В результате в нашей программе каждая собака автоматически является ещё и
млекопитающим, животным и объектом.
Наследование – это заложенный в методологию ООП способ объявить тот факт,
что всякий объект класса X также является и объектом класса Y. То есть если у нас есть класс
"собака", то в описании классов записано, что каждый объект этого класса также принадлежит классу
"млекопитающее", каждое млекопитающее также принадлежит классу "животное", каждое животное также принадлежит
некоему базовому классу "объект". В результате в нашей программе каждая собака автоматически является ещё и
млекопитающим, животным и объектом.
Использование наследования слишком жёстко и однозначно определяет классификацию объектов. В частности, имея набор классов "объект" – "животное" – "млекопитающее" – "собака" пространство нашего манёвра сужено тем фактом, что собака обязана быть живым существом. Появление среди объектов собаки Айбо, не являющейся живым существом, создаст определённые проблемы.
Агрегация – это включение объекта (объектов) одного класса в состав объекта другого класса. Данный подход широко применяется в интерфейсном подходе к проектированию программ, ярчайшим примером которого является COM-технология. В частности, COM-объект может предоставлять наборы интерфейсов тех объектов (делегирование), которые он, грубо говоря, он в себе содержит. Подобный подход также может быть реализован и без использования COM.

Применение агрегации с делегированием интерфейсов также не является лекарством от всех болезней. В частности, там, где применение COM нецелесообразно либо невозможно, полноценная реализация делегирования "вручную" может стать весьма дорогим удовольствием. Кроме того, есть ряд принципиальных моментов:
- Полиморфизм, реализованный через делегирование – это не тот же самый полиморфизм, который заложен в "классические" каноны ООП и основан на наследовании, и поэтому для придания концептуальной стройности проектируемой системе мы вынуждены отказаться от их совместного использования (по крайней мере, в рамках одного логического уровня).
- Когда мы заворачиваем объект в "обложку", мы должны заставить всех "клиентов" иметь дело именно с обложкой, а не с самим объектом, что не всегда возможно и практически всегда не удобно.
- Используя этот механизм, мы отказываемся от многих удобств, предоставляемых средами разработки – автоматический контроль типов, CodeAssist и пр.
Mixin-технология – весьма остроумный способ создания составных классов, при котором класс собирается из составных частей, используя множественное наследование, и при этом сохраняется возможность использования свойств и методов одной составной части другой составной частью.

Особая прелесть заключается в том, что при объявлении составного класса мы можем скомпоновать его именно из тех частей, которые нам необходимы. Например, вместо Class1<Class3> мы можем взять Class1_xp<Class3> (важно только, чтобы Class1_xp<> был потомком IClass1).
Эта технология свободна ото всех недостатков, перечисленных мной при рассмотрении методики "Агрегация", но остаётся ещё ряд нерешённых проблем:
- Мы обязаны явно объявить все возможные составные классы. Чаще всего это никому не мешает, но бывают случаи, когда жизнь оказывается значительно сложнее и многообразнее той картины, которую мы нарисовали на начальном этапе разработки.
-
Логика взаимодействия компонент составного класса описывается либо в самих компонентах, либо непосредственно в составном классе. В этом кроется небольшая проблема. Допустим, у нас есть два интерфейса – I1 и I2. Интерфейс I1 имеет две реализации: в классе С1I1 и С2I1, а интерфейс I2 – соответственно С1I2 и С2I2. Интерфейсы I1 и I2 логически взаимосвязаны между собой. Составной класс CC11 собирается из компонент С1I1 и С1I2, класс СС12 – из С1I1 и С2I2, и ещё возможны варианты CC21 и CC22. Что делать, если С2I1 плохо совместим с С1I2 (выделено красненьким)? Можно эту ситуацию "разрулить" в классе CC21, а можно в С2I1 написать что-то типа:I1 I2 С1I1 С2I1 С1I2 С2I2 CC11 X X CC12 X X CC21 X X CC22 X X if (Self.I1_GetVersion() == 1) {...И то, и другое – не красиво. И не удобно. И не всегда возможно.
| ...template feature in C++ is nothing more than a macro package with a lot of sugar on top.
It's also a macro package that invites implementing huge recursive macro expansions, and that is where the
monstrosity comes in. c2.com/cgi/wiki?CeePlusPlus |
А предлагается на секундочку вынырнуть из зияющих глубин существующих технологий и посмотреть на философскую сторону вопроса.
Для начала разберёмся с тем, что подразумевается под множественной классификацией объектов. А подразумевается исключительно то, что система должна обеспечивать возможность иметь каждому экземпляру именно тот набор интерфейсов, который он иметь обязан.
Например, я являюсь человеком. Для работодателя у меня есть набор интерфейсов "Сотрудник", для жены – "Муж", для детей – "Отец", для родителей – "Сын", для продавца в магазине – "Покупатель", для водителя автобуса – "Пассажир", для программы Notepad, в которой пишется этот текст – "User". По крайней мере, половины из вышеперечисленных наборов интерфейсов волею судьбы у меня могло бы и не быть.
Заметьте, нельзя сказать, что во мне содержатся перечисленные объекты. Я ими всеми являюсь одновременно. Все мои ипостаси мало того что сосуществуют, но ещё и взаимно переплетаются, давая качественно новый эффект. Например, придя в магазин, я говорю: "Здравствуйте, у вас есть памперсы 4-го размера?". Слово "здравствуйте" – это продукт ипостаси "вежливый человек". Интересуюсь памперсами потому что я отец. Смысл фразы – это предложение начать транзакцию между магазином и мной, розничным покупателем.
Итак, информационные сущности (экземпляры) имеют интерфейсы (методы и свойства). Многие интерфейсы можно сгруппировать. Далее будем говорить о наборах интерфейсов. Частный случай набора интерфейсов – "одинокий" интерфейс. О наборах интерфейсов можно сказать следующее:
- Некоторые наборы интерфейсов подразумевают, что объект обладает и другими наборами интерфейсов (например, из того, что человек является отцом однозначно следует, что он мужчина), и в этом случае мы с чистой совестью на своей UML-диаграмме можем нарисовать отношение "Generalization", обозначив этим классическое ООПовское наследование.
- Некоторые наборы интерфейсов уживаются вместе, хотя могут жить и порознь (файл может являться документом, а может им и не являться; документ может быть файлом, а может файлом и не быть).
- Некоторые наборы интерфейсов логически противоречат друг другу (кошка может быть кем угодно – животным, членом семьи, другом, игрушкой, но собакой быть не может).
- Бывает так, что присутствие у объекта набора интерфейсов определяется свойством другого набора интерфейсов, присущего этому объекту (человек может быть клиентом табачного ларька только в том случае, если значение его свойства "Возраст" больше либо равно 18).
- Бывает так, что присутствие у объекта набора интерфейсов определяется контекстом, т.е. свойствами других объектов. Это всего лишь некоторая глобализация предыдущего пункта.
Пункт 2 будет использован как обоснование необходимости множественной классификации на уровне экземпляров, пункты 4 и 5 – для обоснования мутации объектов, которая будет рассмотрена ниже.
А теперь давайте (наконец то) введём определение:
Класс – это именованный набор интерфейсов.
И ещё одно:
Тип – это вся совокупность интерфейсов и их реализаций, присущая объекту.
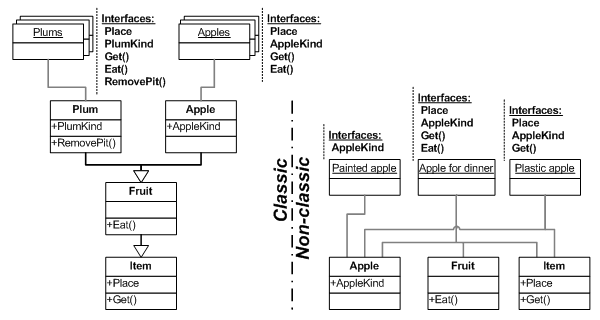
В классическом ООП эти понятия трактуются немножко по-другому. Двумя словами это можно выразить так: тип – вся совокупность интерфейсов и их реализаций, присущая объекту; класс – тип, не являющийся простым. Пожалуйста, почувствуйте разницу, иначе дальнейшее изложение будет для Вас бессмысленной тарабарщиной.
 Можно возразить, что всю совокупность
интерфейсов объекта тоже можно назвать одним словом, и тогда класс также становится типом (так, как это
показано на рисунке справа). Для того, чтобы разночтений не возникало, введём определение элементарного класса:
Можно возразить, что всю совокупность
интерфейсов объекта тоже можно назвать одним словом, и тогда класс также становится типом (так, как это
показано на рисунке справа). Для того, чтобы разночтений не возникало, введём определение элементарного класса:
Элементарный класс – именованный набор интерфейсов, не подлежащий дальнейшей декомпозиции. Каждый отдельно взятый интерфейс может принадлежать только одному элементарному классу.
Элементарный класс – это тот платоновский эйдос, который может быть присущ объекту, действию или явлению, и глубже которого двигаться либо невозможно, либо не нужно.
Теоретически возможно два подхода к типизации объектов:
- Каждый тип (сочетание элементарных классов), какой только возможен, программист должен объявить явно и аккуратно, с любовью, отшлифовать его логику. Можно чуть-чуть слукавить, применив шаблоны, но суть от этого не меняется. Этот подход применяется в 100% языков программирования. Даже удивительно.
- Явного объявления требуют только элементарные классы. Тип объекта определяется как сочетание элементарных классов.
Пока программа оперирует достаточно простыми, однозначными, и, как правило, искусственными сущностями (Button, ComboBox, Stack, Connection, 3DLine и т.д.), первый способ типизации оказывается вполне достаточен. Но при столкновении с чудовищным многообразием реального мира отсутствие персонализированной "тонкой настройки" набора интерфейсов объекта может иметь неприятные последствия. А именно:
- Предметная область слишком многообразна, и поэтому необходимо слишком большое количество классов, мало отличающихся друг от друга. Решаемая программой задача не то чтобы слижком сложна (полное её описание помещается, допустим, на десяти страницах), но количество строк кода перевалило за сто тысяч, большая часть которых написана операцией Copy/Paste. Никто не понимает, как это всё работает. Проще выбросить, чем переделать. Провал проекта.
- Предметная область слишком многообразна, и поэтому вместо слишком большого количества классов, мало отличающихся друг от друга, мы создаём классы-супертяжеловесы, которые в зависимости от своих внутренних параметров могут вести себя совсем по-разному. Классов получилось не очень много, но количество строк кода опять перевалило за сто тысяч, большая часть которых начинается оператором IF. Никто не понимает, как это всё работает. Проще выбросить, чем переделать. Провал проекта.
- Предметная область слишком многообразна, но мы её упростим, переложив особо скользкие моменты на хрупкие плечи пользователя. Пользователи стонут, база данных противоречива и не соответствует уже ничему. Клиенты уходят к конкурентам. Провал проекта.
- Предметная область проста и стабильна. Методологического арсенала ООП вполне хватает. Всё сделано изящно и просто. Со временем все ошибки выловлены. Прибыли растут. Success story.
Итак, из всех этих рассуждений следует, что при разработке многих систем для типизации объектов недостаточно поддержки множественной классификации на уровне описаний классов. Должна присутствовать возможность задания перечня классов непосредственно для каждого объекта.
Смысл технологий программирования уже давно смещается с построения эффективных алгоритмов в сторону построения эффективных моделей предметных областей. Если технологическое нововведение разумно с точки зрения более точного отражения внутренней логики предметных областей, то это нововведение уже оправдано.
Давайте попробуем отказаться от основополагающей роли концепции наследования. И увидим, как это хорошо.
Синергизм классов
Принадлежность объекта двум классам может качественно его преображать.
Рассмотрим, что может произойти, если объект А принадлежит классам X и Y одновременно.
- Объект А поддерживает все интерфейсы Ix и Iy классов X и Y.
- Интерфейсы Ix объекта А могут быть реализованы не так, как интерфейсы другого объекта, принадлежащего классу X, но не принадлежащего классу Y.
Сочетание классов X и Y назовём виртуальным классом XY, появляющимся в системе как следствие появления классов X и Y. Вооружившись комбинаторикой, несложно подсчитать, что с ростом количества элементарных классов количество виртуальных растёт лавинообразно. Например, для трёх элементарных классов количество виртуальных равно 4, для четырёх – 10, для десяти – 1013. Но это не должно нас пугать.
В классическом ООП полиморфизм объектов основывается на механизме наследования. Отказавшись от наследования, мы можем всю тяжесть полиморфизма переложить на синергизм классов. Поясню на примере.
Допустим, проектируется система, в которой некоторые прикладные объекты сохраняются в базу данных. Например, клиенты записываются в таблицу Clients, заказы – в таблицу Orders. Обычно создают родительский класс clPersistent, имеющий методы Read() и Save(), и классы clClient и clOrder порождают (возможно, косвенно) от Persistent.
Мы тоже создадим класс clPersistent, имеющий методы Read() и Save() и классы clClient и clOrder, таких методов не имеющие. Запись реквизитов контрагента в базу данных будет производиться в процедуре Save() виртуального класса (clPersistent, clClient), реквизитов заказа – в процедуре, реализованной для (clPersistent, clOrder).
Виртуальный класс – это тоже класс. Он может иметь конструктор и деструктор (весьма полезные идиомы ООП). Оставим вопрос открытым, может ли виртуальный класс иметь собственные интерфейсы либо он должен для этого делать дополнительную классификацию объекта (проще говоря, в список элементарных классов добавлять что-то ещё).
Абстрактные классы
| The man thinks, the horse thinks, the sheep thinks, the cow thinks, the dog thinks. The fish doesn't think. The fish is mute. Expressionless. The fish doesn't think, because the fish knows everything. Iggy Pop, "This is a Film" |
Есть у абстрактных классов одно спорное, но весьма полезное свойство – крайняя неприязнь к вызову абстрактных методов, в результате чего в релизах программ, как правило, все абстрактные методы получают свою реализацию в классах-потомках. При реализации полиморфизма через виртуальные классы программа, написанная забывчивым разработчиком, не будет аварийно завершаться с сообщением об ошибке. Она просто не будет выполнять требуемое действие. Как к этому относиться – не знаю.
Шаблоны (templates)
При использовании технологии множественной классификации шаблоны не нужны. В частности, вместо
CFoo<CBar> FooBar;можно написать что-то вроде
(CFoo, CBar) FooBar;
Не знаю как кто, но я бы об избавлении от шаблонов не жалел ни секунды.
Реализации интерфейсов при множественной классификации
Интерфейс объекта может быть процедурой, функцией либо атрибутом. Особенно интересны процедуры и функции, так как только они включают в себя программный код и могут быть полиморфными. Итак,
Процедура – интерфейс, получающий от вызывающей стороны некий набор параметров и выполняющий заложенные в реализацию действия.
Функция – интерфейс, получающий от вызывающей стороны некий набор параметров, выполняющий заложенные в реализацию действия и возвращающий вызывающей стороне одно и, как любят говорить математики, только одно значение.
Рассмотрим абстрактный пример. В системе есть классы X и Y. Класс X имеет метод M, реализованный в контексте класса X (Mx) и в контексте виртуального класса XY (Mxy). Если вызвать метод M объекта A, одновременно принадлежащего классам X и Y, какая из реализаций (Mx или Mxy) должна отработать? "Mxy" – неправильный ответ. В системе ведь может оказаться ещё один класс Z и ещё одна реализация метода M (Mxz), и выбор между Mxy и Mxz объекта B, принадлежащего одновременно классам X, Y и Z, может стать совсем невыносимым.
Выход из этой ситуации только один – всегда вызывать все подходящие реализации методов. В каком порядке вызывать реализации методов? Можно предложить следующие варианты:
- Сначала в каком-то определённом порядке вызываются реализации, принадлежащие самым виртуальным из всех виртуальных классов, в самом конце – реализацию, заложенную в элементарный класс. В приведённом выше примере цепочка будет выглядеть так: Mxyz – Mxy – Mxz – Mx
- Можно сделать наоборот: Mx – Mxy – Mxz – Mxyz
- Вызывать все реализации в произвольном порядке (либо даже в параллельных потоках).
Вместо того, чтобы мучаться выбором того, какой вариант является более универсальным, предлагается предоставить право выбора разработчику того элементарного класса, в котором метод объявлен. И предоставить возможность управлять последовательностью вызова в процессе исполнения, для чего выдумать несколько операторов:
call_next_method – вызывает следующую реализацию из заранее сформированной цепочки и затем возвращается в это же место (как в CLOS).
stop_method – останавливает выполнение цепочки и передаёт управление вызывающей программе.
Для функций я бы ещё открыл доступ к возвращаемому значению на чтение. И пусть функция сама решает, как быть – вписать свою версию, оставить без изменений ранее вычисленную, вернуть сумму или... есть масса вариантов. Естественно, варианты реализации функции нельзя пускать в параллельные потоки.
Статические и динамические методы
Рассмотренные ранее "умные" методы всем хороши. И полиморфны, и расширяемы. Но есть у них два недостатка:
- Реализация таких методов весьма накладна. Определение перечня задействованных реализаций в любом случае намного дольше отработки процессорной инструкции CALL.
- Они никогда не смогут быть in-line.
Поэтому в любом случае должна присутствовать возможность делать методы статическими. Если разработчик твёрдо уверен, что для метода Mx никогда не придётся делать расширение Mxy или Mxz, почему бы не вызывать такой метод простой инструкцией CALL?
Мутация объектов
Мутация – это динамическое изменение типа экземпляра в ходе выполнении программы.
Некоторые теоретики утверждают, что от этой идеи нужно отказаться раз и навсегда, т.к. она потенциально очень опасна. Другие говорят, что мутация объектов имеет место в реальном мире, и поэтому она логична и в мире виртуальном.
Где-то выше по тексту мы признали главенство эффективного построения моделей предметных областей, и поэтому постановим, что возможность мутации должна быть. А от опасностей попробуем защититься.
Давайте разберёмся, чем опасна мутация. Единственное, что приходит в голову, так это то, в результате какой-то операции тип переменной может измениться так, что дальнейший код работать не будет:
CFoo *Foo = new CFoo(); Foo->Name = "My Foo"; DoSomethingStrange(&Foo); // переменную Foo мутировали в CBar* cout << Foo->Name; // Не работает! Класс CBar не имеет свойства Name.
Компилятор твёрдо уверен, что переменная Foo имеет тип CFoo*, знает по какому смещению лежит свойство Name, и в результате либо считает какой-то мусор вместо Name, либо сразу вылетит с GPF.
В тех языках программирования, в которых все переменные принадлежат типу Variant (как правило, такое бывает в интерпретируемых языках), иногда можно встретить тексты вроде такого:
MyVar = 1; Message(MyVar+1); // "2" MyVar = "Text string"; Message(MyVar+1); // "Text string1"
Такой стиль программирования безусловно ужасен. Подобные упражнения мы не будем рассматривать в качестве той полноценной мутации, которой хотим достигнуть.
В тех языках программирования, в которых класс объекта не является составным (т.е. во всех существующих на настоящий момент), любая мутация представляет собой кардинальную смену типа объекта. Если переменная Foo меняет свой класс с CFoo на CBar, то в результате выполняется две операции:
- Переменная Foo перестаёт принадлежать классу CFoo. Естественно, после этого вся выполняющаяся после этого логика может перестать работать.
- Переменной Foo присваивается класс CBar.
Концепция множественной классификации допускает более мягкий вариант мутации объектов. Можно так изменять тип объекта, чтобы (как это сказать по-русски?) объявленный тип переменной не терялся. Заранее извиняюсь за объёмный код на неизвестном науке языке программирования.
enum eGender {
Male, Female
}
class cMale {
autoclassify as cHuman; // Проинформируем компилятор о том, что cMale = (cHuman, cMale)
public
var Wife as cFemale;
}
class cFemale {
autoclassify as cHuman;
public
var Husband as cMale;
}
class cHuman (
private
var Geneder as eGender;
public
var Name as String;
function GetGender() as eGender {
Result = Gender;
}
procedure SetGender(AGender as eGender) {
if (AGender = Female) {
declassify this as cMale;
classify this as cFemale;
} else if (AGender = Male) {
declassify this as cFemale;
classify this as cMale;
} else {
declassify this as cMale;
declassify this as cFemale;
}
}
) // cHuman
// Процедура, внутри которой проблем не возникнет
procedure QueryAndSetGender(Somebody as cHuman) {
var Choice as eGender;
Choice = App.AskUserChoice("Somebody is", Somebody.GetGender(),
eGender::Male, "male",
eGender::Female, "female"); // Такая гипотетическая функция
if (Choice <> null)
Somebody.SetGender(Choice);
// Ничего не нарушилось. Somebody по-прежнему принадлежит классу cHuman
// declassify Somebody as cHuman; // <<<< А вот это не пропустит компилятор
} // QueryAndSetGender
// Процедура, в которой мы обманем компилятор
procedure Male2Female(AMale as cMale) {
if (App.MessageBox("Are you sure?", MB_YES + MB_NO + MB_DEFBUTTON2) = IDYES)
AMale.SetGender(eGender::Female); // Проблема: как такое запретить компилятором?
if (AMale.Wife <> null) // Ой, началось...
App.MessageBox(AMale.Name + " is married to " + AMale.Wife.Name, MB_OK);
else
App.MessageBox(AMale.Name + " isn`t married", MB_OK);
} // Male2Female
Компилятор можно обмануть и каким-нибудь более изощрённым методом.
Как всегда, проблема обмана компилятора за счёт запутывания логики может быть решена несколькими способами:
- Сделать компилятор до такой степени интеллектуальным, что его нельзя будет обмануть. Вряд ли это возможно. Фантазия багописателя поистине виртуозна и неистощима. Возможно, я ошибаюсь.
- Ограничиться предупреждениями для простейших случаев, но в принципе такие безобразия разрешить. В этом случае придётся легитимизировать NULL. Т.е. все свойства и функции тех классов, к которым объект уже не принадлежит, возвращают NULL, вызовы процедур и изменения атрибутов состояние системы не изменяют. Таким образом, процедура Male2Female сообщит, что клиент не женат.
- Можно не вводить в язык опасный оператор declassify, а весь механизм мутации ограничить совершенно безопасным оператором classify.
Строгая типизация
Спустимся с вершин теоретических умопостроений и вспомним, что алгоритмы пишутся на языках программирования в виде обычных текстов, содержащих имена переменных, константы, операторы и т.п.
Есть программисты, которые любят строгую типизацию, есть программисты которые не любят строгую типизацию. Это почти религиозный вопрос. Можно долго рассуждать о преимуществах того и другого, скажу только, что при множественной классификации без неё не обойтись. И вот почему.
Предположим, у нас есть переменная objWindow. Есть класс clDialog (диалоговое окно, которое можно открыть функцией Open) и класс clFoldingWindow (створчатое окно, элемент справочника товаров, который можно прочитать из БД функцией Open) В программе встречается следующая строка:
objWindow.Open();
Если нет строгой типизации на этапе синтаксического разбора текста программы, то может возникнуть такая ситуация, что objWindow в момент выполнения этого оператора будет одновременно принадлежать к классу clDialog и к классу clFoldingWindow (очень удобно, между прочим). Что мы при этом должны сделать? Открыть диалоговое окно или прочитать информацию из БД? В системах программирования с поздним связыванием хотя бы на этапе выполнения можно это выяснить. Получается, что мы вынуждены использовать строгую типизацию на этапе синтаксического разбора. И если уж у нас получилось так, что переменная objWindow объявлена как:
Var objWindow as (clDialog, clFoldingWindow);
то будь добр написать конструкцию вроде
clDialog::(objWindow.Open());
Если же переменная objWindow объявлена как:
Var objWindow as clDialog;
то вызов команды открытия окна достаточно написать и так:
objWindow.Open();
и не важно, что реально в момент выполнения objWindow будет принадлежать ещё и классу clFoldingWindow. Из объявления переменной понятно, что нужно открыть диалоговое окно.
Будем считать вопрос строгой типизации закрытым.
Реляционные БД и множественная классификация
Ни для кого не секрет, что объектно-ориентированное программирование весьма посредственно сочетается с теорией и практикой реляционных баз данных. Общепринятым мнением насчёт возможных путей разрешения возникающих противоречий является необходимость внесения изменений и дополнений в теорию реляционных БД. Считается, что проблемы кроются именно там, а не в теоретических основах ООП.
| Мощно задвинул! Внушаить! Х. Моржов |
Проблема связана с тем, что при хранении объектов, классы которых образуют сложную иерархию наследования, очень сложно бывает выбрать такую стратегию отображения классов на таблицы РБД, которая бы устраивала всех. Выработано (и даже канонизировано) несколько подходов, но ни один из них, на мой взгляд, не является универсальным решением, свободным ото всех недостатков.
Смею заявить, что отказ от концепции наследования в пользу множественной классификации снимает проблему отображения классов на таблицы РБД раз и навсегда. Из всех подходов к проблеме мэппинга остаётся один (самый логичный!): один класс – одна таблица (или таблица с подчинёнными таблицами). Подчинённые таблицы бывают нужны потому, что требование атомарности полей никто не отменял.
Хорошая сочетаемость предлагаемой в этой статье парадигмы со стройной и математически обоснованной теорией реляционных баз данных является неплохим аргументом в пользу того, что описанный подход имеет право на жизнь.
Изменения в технологии проектирования
В этом разделе попробуем разобраться, каким образом предлагаемая технология может облегчить жизнь программистам и архитекторам информационных систем. Для начала вспомним стандартную последовательность действий, применяемую при использовании классического ООП (здесь опущены стадии постановки задачи, написания ТЭО, формирования проектной команды, документирования и пр.):
- Выделение сущностей, присутствующих в предметной области. Например, при проектировании ИС для зоопарка такими сущностями могут быть слон, тигр Атилла, тигрица Лада, жираф, страус, корм для хищников, банковский счёт, клетка для птиц, вольер, подсобное хозяйство, заблудившийся посетитель, ветеринар Семён Палыч, налоговая инспекция, докладная записка о нецелевом использовании мяса и многое другое. Всё это проектировщик загружает в свою голову в ходе долгих бесед со специалистами, вникания в суть документооборота, наблюдений за происходящими процессами и т.д.
- Обобщение. На все выделенные ранее сущности навешиваем ярлычки. Про слона, жирафа и тигров скажем, что они млекопитающие, про тигров и сов – что они хищные, про ветеринара, уборщицу и системного администратора – что они сотрудники, про вольеры и клетки – что они являются местами обитания. Когда ни один из объектов не остался без ярлычка, нужно проанализировать сочетания ярлычков и сделать так, чтобы на каждом объекте или явлении оказалось повешено по одному главному ярлыку, называемому классом. Все повешенные ранее ярлычки выстраиваем в иерархию так, чтобы они стали предками (субклассами) тех классов, от которых мы будем порождать объекты.
- Описание взаимодействия объектов. Хищники поедают мясо, травоядные – сено, ветеринар лечит животных, билетный кассир принимает деньги, а завхоз их тратит, экскурсовод обслуживает посетителей, а главбух – налоговую инспекцию.
- Описание интерфейсов (свойств и методов) классов. Хотя, впрочем, обычно это делается параллельно двум предыдущим пунктам.
- Реализация модели в программном коде и в структуре базы данных.
Чем точнее мы сможем описать логику предметной области набором ярлычков и их интерфейсов, тем меньше потом придётся переделывать. Комизм ситуации заключается в том, что все этапы проходят в условиях неполноты, изменчивости и противоречивости имеющейся в наличии информации. Достаточно лёгкого дуновения ветерка, и стройная иерархия начинает заваливаться.
Постоянно появляются объекты, для которых разработанная (а возможно, уже и реализованная) система классов не подходит. Ну кто ж мог знать заранее, что сторожевые собаки, охраняющие гаражи – это тоже животные, тоже едят корм, но экспонатами не являются?
Многие модные паттэрны проектирования (компонентный подход, гомоморфные иерархии, mixinы и др.) большей частью предназначены именно для минимизации потерь, вызванных неудачным построением иерархии классов.
Сила множественной классификации заключается в том, что разработчик избавляется от необходимости выполнения не вполне корректного с логической точки зрения, очень ответственного и весьма трудоёмкого процесса выстраивания иерархии. Если есть большое желание что-то обобщить – пожалуйста, обобщайте, но насильно никто этого делать не заставляет.
Вот как тот же самый техпроцесс будет выглядеть в случае применения множественной классификации:
- Выделение сущностей, присутствующих в предметной области. Куда ж без этого?
- Обобщение. На все выделенные ранее сущности навешиваем ярлычки (классы). Если есть возможность и желание заняться обобщением ярлычков, то делаем это. При проектировании системы классов руководствуемся исключительно максимизацией наиболее точного соответствия системы классов тому множеству понятий, которое присутствует в предметной области.
- Описание взаимодействия объектов.
- Описание интерфейсов (свойств и методов) классов.
- Реализация модели в программном коде и в структуре базы данных.
Это сродни логическому программированию. Системе сообщается набор сведений, известных о предметной области, и в результате получается готовая автоматизированная система. Если поступила дополнительная ранее не учтённая информация, просто добавляем её в набор правил и радуемся тому, как быстро получилось удовлетворить пожелания клиента. Это, конечно, слишком идиллическая картина, но, согласитесь, предпосылок для её появления стало значительно больше, чем при использовании устоявшихся "классических" подходов.
Что дальше?
Дальше можно развиваться в следующих направлениях:
- Нужно ещё как следует отшлифовать методологию. Наверняка есть ещё масса проблем, тонкостей и нестыковок, упущенных мной из виду.
- Нужно проработать тему модульности программ. Проблема назрела донельзя. Если удастся решить её на базе технологии множественной классификации, благодарные потомки нас не забудут.
- Поговорили о синергизме классов, но ни слова не сказали о синергизме экземпляров. Очень интересная и глубоко философская тема, достойная нескольких докторских диссертаций. Суть идеи состоит в том, что объекты, собираясь вместе (взаимодействуя прямо либо косвенно), теоретически образуют некий виртуальный мегаобъект, обладающий своими свойствами и поведением. Тема эта сродни теме мультиметодов, но гораздо шире и глубже. Меня не покидает ощущение, что на этой ниве можно найти больше золотых самородков, чем на грядке множественной классификации.
Заключение
Были инкапсуляция, наследование и полиморфизм. Наследование сложили на задворки истории, и добавили множественную классификацию. Получилось: инкапсуляция, множественная классификация, полиморфизм.
Выяснили, что множественная классификация:
- является логическим продолжением вектора развития программно-технологической мысли;
- избавляет от таких противоестественных вещей как абстрактные классы и шаблоны;
- легализует мутацию экземпляров;
- хорошо сочетается со строгой типизацией, и, более того, требует её в весьма жёсткой форме;
- лучше классического подхода сочетается в теорией РБД;
поднимает процесс проектирования на уровня логического программирования.— Ты всёсла поняласла? — спросила Тофсла.
— Ни каплисла! — сказала Вифсла и плюнула вишнёвой косточкой в судью.
И самое главное, что множественная классификация в принципе реализуема.
Вопросы есть?
|
Удивительное дело! Когда занимаешься теоретическими построениями в области технологий программирования, попеременно складываются два противоположных ощущения: "всё придумано до нас, и ничего нового выдумать просто невозможно" и "область настолько необъятна и причудлива, что хватит дела не только нам, но и нашим детям и внукам". Всё-таки, мне кажется, второе утверждение ближе к истине.